Schlag den Roboter – Maschinelles Lernen erfahren
Schlag den Computer im Mini-Schach (online).
Hinter den jüngsten Entwicklungen im Bereich künstliche Intelligenz stecken vor allem maschinelle Lernverfahren. Das dazugehörige Fachgebiet beschäftigt sich mit Algorithmen, die sich durch Erfahrung im Laufe der Zeit verbessern. Verstärkendes Lernen ist ein von der Psychologie inspiriertes Paradigma des maschinellen Lernens: Der Computer lernt durch Belohnung und Bestrafung in Interaktion mit seiner Umgebung eine Aufgabe zu meistern, indem er versucht, die mögliche Belohnung zu maximieren. Dieser Beitrag stellt eine Website vor, die das Prinzip des verstärkenden Lernens anhand eines Mini-Schachspiels erfahrbar macht.
Das Spiel
In diesem “Mini-Schach” übernimmt der Mensch die Rolle der Äffchen, der Computer steuert die Roboter. Mini-Schach (oder Hexapawn) geht aus einer Idee von Martin Gardner hervor, der damit bereits 1958 maschinelles Lernen erklärte.

Jede Spielfigur bewegt sich wie ein Bauer, d. h. sie kann nur vorwärts gehen und gegnerische Figuren nur diagonal schlagen. Eine Seite hat gewonnen, wenn sie es schafft
- eine eigene Spielfigur an das andere Ende des Spielfeldes zu führen,
- alle gegnerischen Figuren zu schlagen,
- oder dafür zu sorgen, dass der Gegner in der nächsten Runde keinen Spielzug mehr ausführen kann.
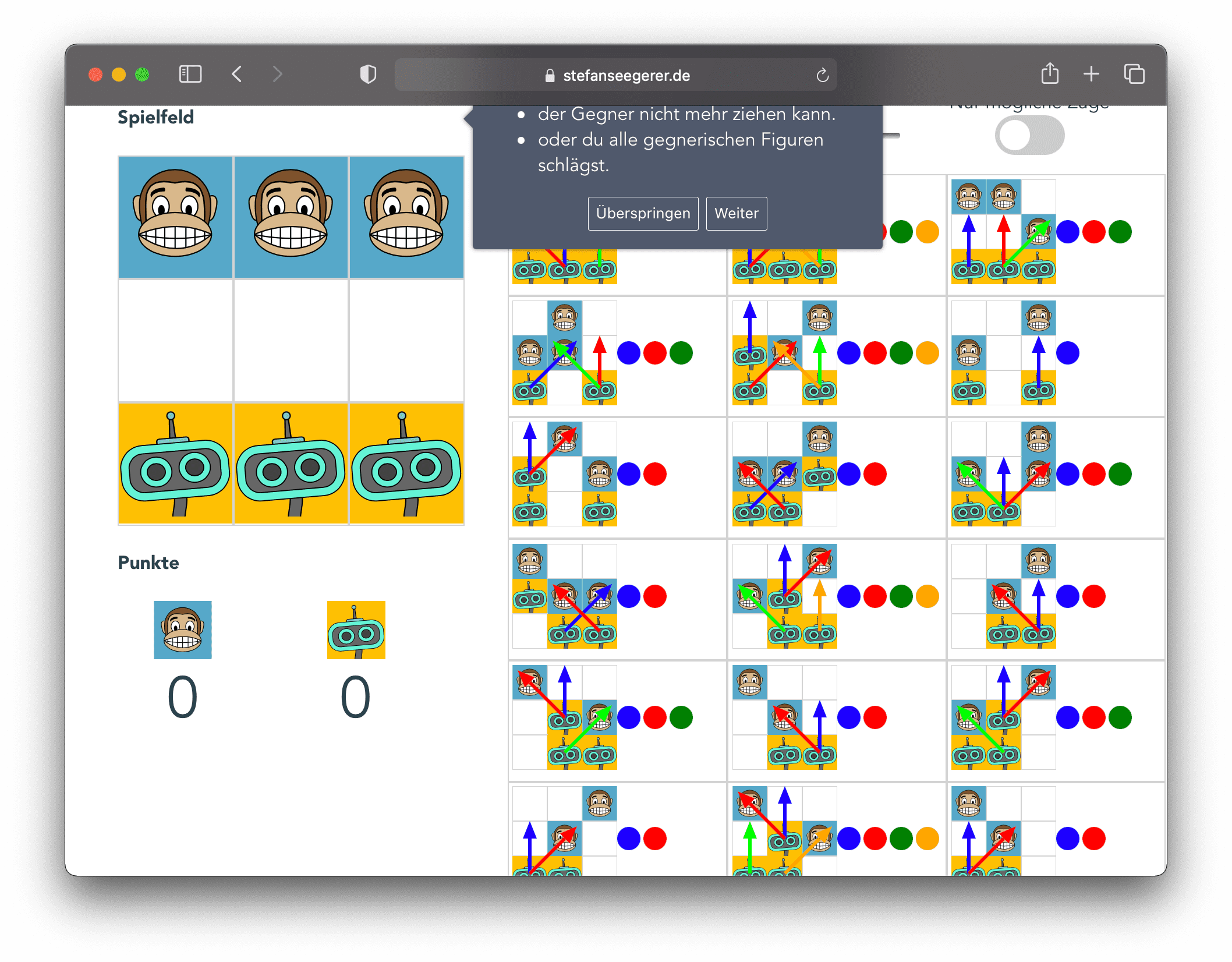
Die menschliche Spielerin bzw. der menschliche Spieler beginnt. Sie bzw. er kann sich frei gemäß der Spielregeln bewegen. Danach ist der Computer an der Reihe. Dieser vergleicht das aktuelle Spielfeld mit den Zugmöglichkeiten und wählt die passende Spielsituation aus den gegebenen Möglichkeiten (rechts im Bild) aus.
Im Anschluss zieht der Computer zufällig eines der farbigen Tokens, die sich neben der jeweiligen Spielsituation befinden. Die Farbe des Tokens bestimmt, welcher Zug ausgeführt wird. Wird beispielsweise ein rotes Token gezogen, wird der Roboter dem roten Pfeil folgend bewegt.

Dieses Vorgehen wird solange wiederholt, bis ein Gewinner feststeht. Bevor eine neue Runde gespielt wird, passt der Computer nun seine Strategie wie folgt an:
- Computer hat gewonnen: Ein Token in der Farbe des letzten, siegbringenden Spielzugs wird zusätzlich auf das Feld dieses Spielzugs gelegt.
- Mensch hat gewonnen: Das Token, das den letzten Zug der Computer-Spielerin bzw. des Computer-Spielers bestimmt hat, wird entfernt.

Hintergrund
Zunächst wird der Computer kaum eine Chance haben zu gewinnen, da er seine Bewegungen zufällig wählt (indem ein Token gezogen wird). Je mehr Spiele der Computer beendet, desto besser wird er: Er „lernt”, welche Züge ihm zum Sieg verhelfen und welche er vermeiden sollte, da sie in der Vergangenheit in einer Niederlage endeten. So wird die Strategie des Computers schrittweise verfeinert. Da der Computer für das Verlieren bestraft und für das Gewinnen belohnt wird, sprechen wir auch von bestärkendem Lernen (Reinforcement Learning) – ein Lernen durch Belohnung und Bestrafung:
- Bestrafung = Wegnehmen eines Tokens bei einem Spielzug, der zur Niederlage führte
- Verstärkung = Hinzufügen eines Tokens bei einem Spielzug, der zum Sieg führte
Durch dieses Vorgehen werden bei den jeweiligen Spielzügen diejenigen Züge „aussortiert”, die Niederlagen zur Folge hatten, sodass irgendwann nur noch „gute” Züge übrig bleiben. In der Praxis würde man Strategien, die nicht zum Erfolg führen, nicht sofort eliminieren, sondern nur die Wahrscheinlichkeit ihres Auftretens verringern. So lernt die KI nach und nach, welche Strategie in welcher Situation wohl am besten geeignet ist, schließt einzelne Strategien, die nicht in jedem Fall zum Erfolg geführt haben, aber nicht sofort vollständig aus.
Ein Computer kann auf diese Weise allein durch die Kenntnis der Spielregeln oder möglicher Eingaben lernen, ein Spiel zu gewinnen. Lernt ein Computer etwa das Videospiel Super Mario zu spielen, wird er zunächst nur wahllos Eingaben tätigen. Das könnte dazu führen, dass er minutenlang nur stehen bleibt oder mehrfach in denselben Gegner hineinläuft. Er analysiert dabei die Objekte bzw. Pixel im Bild und reagiert mit Eingaben. Sein Ziel ist es, die erreichte Punktzahl im Spiel zu maximieren, die Punkte fungieren hier als Belohnung. Je weiter der Computer nach rechts vorrücken kann, desto größer fällt die positive Verstärkung aus. Mit der Zeit wird er so beispielsweise lernen, dass Springen seine Belohnung erhöht, wenn sich ein Gegner unmittelbar rechts von ihm befindet, da er durch das Überspringen des Gegners weiter im Level vorankommt. Auf diese Weise verbessert sich das Vorgehen eines KI- Systems in einem Spiel Stück für Stück, wobei das System immer versucht, seine Belohnung (oder genauer: eine bestimmte Funktion) zu maximieren.
Computer können aus Erfahrung lernen und so von rein zufälligem Handeln zu einer effizienten Spielstrategie kommen.
Übrigens lässt sich das Spiel auch analog spielen.