So Lernen Maschinen!
Wie “lernen” Autos selbstständig autonom und dabei unfallfrei zu fahren? Wie schaffen es Computer, Krebszellen zu erkennen? Und warum weiß der Online-Shop, was ich noch kaufen möchte? Hinter den jüngsten Fortschritten im Bereich künstliche Intelligenz (KI) stecken vor allem sogenannte maschinelle Lernverfahren – Algorithmen, die sich durch Erfahrung im Laufe der Zeit verbessern, also “lernen”.
Maschinelles Lernen und KI
Maschinelles Lernen unterscheidet sich teilweise deutlich von den Algorithmen, wie sie Schülerinnen und Schüler üblicherweise im Informatikunterricht kennenlernen und bei denen man Schritt für Schritt nachvollziehen kann, wie Eingabedaten in Ausgabedaten umgewandelt werden. Es unterscheidet sich aber auch von anderen, “klassischen” (oder auch symbolischen) Ansätzen der künstlichen Intelligenz: In “klassischen” KI-Systemen wird Wissen explizit im Computer repräsentiert, beispielsweise durch Modellierung der zugrundeliegenden Fakten und Regeln. Aus dieser “Wissensbasis” können von einem “wissensverarbeitenden System” logische Schlüsse gezogen werden, um für Eingabedaten entsprechende Ausgaben abzuleiten. Beim maschinellen Lernen hingegen werden auf Basis einer typischerweise großen Menge an Daten Regeln, Verhaltensweisen oder Muster abgeleitet bzw. identifiziert – also “gelernt”. Das Gelernte wird in einem sogenannten Modell gespeichert und kann im Anschluss auf neue Daten angewendet werden. Während es bei klassischer KI also unsere Aufgabe ist, Wissen so zu modellieren, dass es explizit in einem Computersystem dargestellt und verarbeitet werden kann, müssen beim maschinellen Lernen Daten so aufbereitet und ein (allgemeines) maschinelles Lernverfahren so konfiguriert werden, dass ein Modell aus den Daten generiert werden kann.

Maschinelles Lernen wird vor allem überall dort eingesetzt, wo es aufgrund der Charakteristik des Problems nicht effizient möglich ist, das Wissen so explizit zu repräsentieren, dass es ein Computer verarbeiten kann. Wollen wir eine Katze auf einem Bild erkennen, suchen wir nach vier Pfoten, einem Fell, Schnurrhaaren, usw. Explizite Regeln für all das aufzuschreiben, ist jedoch alles andere als leicht. Wie sieht eine allgemeine Beschreibung für das Erkennen von vier Pfoten, dem Fell, Schnurrhaaren, usw. aus, die ein Computer verarbeiten kann? Außerdem haben wir in der Realität oft mit Unsicherheiten zu kämpfen, so sind vielleicht nicht immer alle vier Pfoten zu sehen. Obwohl uns Menschen solche Entscheidungen intuitiv leicht fallen, ist es schwierig bis unmöglich dieses Wissen innerhalb des Computers explizit zu repräsentieren. Ein maschinelles Lernverfahren wird auf Basis der Daten selbst Merkmale finden, die ihm beispielsweise helfen Katzen zu erkennen – nicht zwingend jene Merkmale, die wir als Menschen verwendet hätten.
Wie aber können maschinelle Lernverfahren nun auf Basis von Daten Regeln und Muster finden und damit z.B. Katzen auf Bildern erkennen? Wie können diese Zusammenhänge auf neue, unbekannte Daten übertragen werden? Kurzum: Wie lernt eine Maschine?
Diesen Fragen wollen wir in diesem Artikel nachgehen. Dabei werden wir zwischen drei Möglichkeiten (oder auch Paradigmen) unterscheiden, wie Maschinen lernen können:
- mit beschrifteten Daten durch überwachtes Lernen (supervised learning)
- mit unbeschrifteten Daten durch unüberwachtes Lernen (unsupervised learning)
- und durch Belohnung und Bestrafung mit verstärkendem Lernen (reinforcement learning)
Im Folgenden soll uns eine Roboterfigur helfen, die verschiedenen Verfahren kennenzulernen. Der Roboter ist hierbei lediglich eine Analogie zu einem Computer, der ein maschinelles Lernverfahren ausführt.

Überwachtes Lernen (supervised learning)
Für viele Kinder ist ein Hund die erste bewusste Begegnung mit einem Tier (“ein Wauwau”). Zunächst wird ein Kind diese Bezeichnung auch auf andere Tiere mit vier Beinen anwenden, bspw. Katzen und Kühe. Durch weitere Begegnungen lernt das Kind nun, dass andere Tierarten auch andere Namen tragen, wie “Mietz Mietz” oder “Muh Muh” und kann bald auch ohne explizite Beschreibung die Tiere anhand ihrer Charakteristika zuordnen.
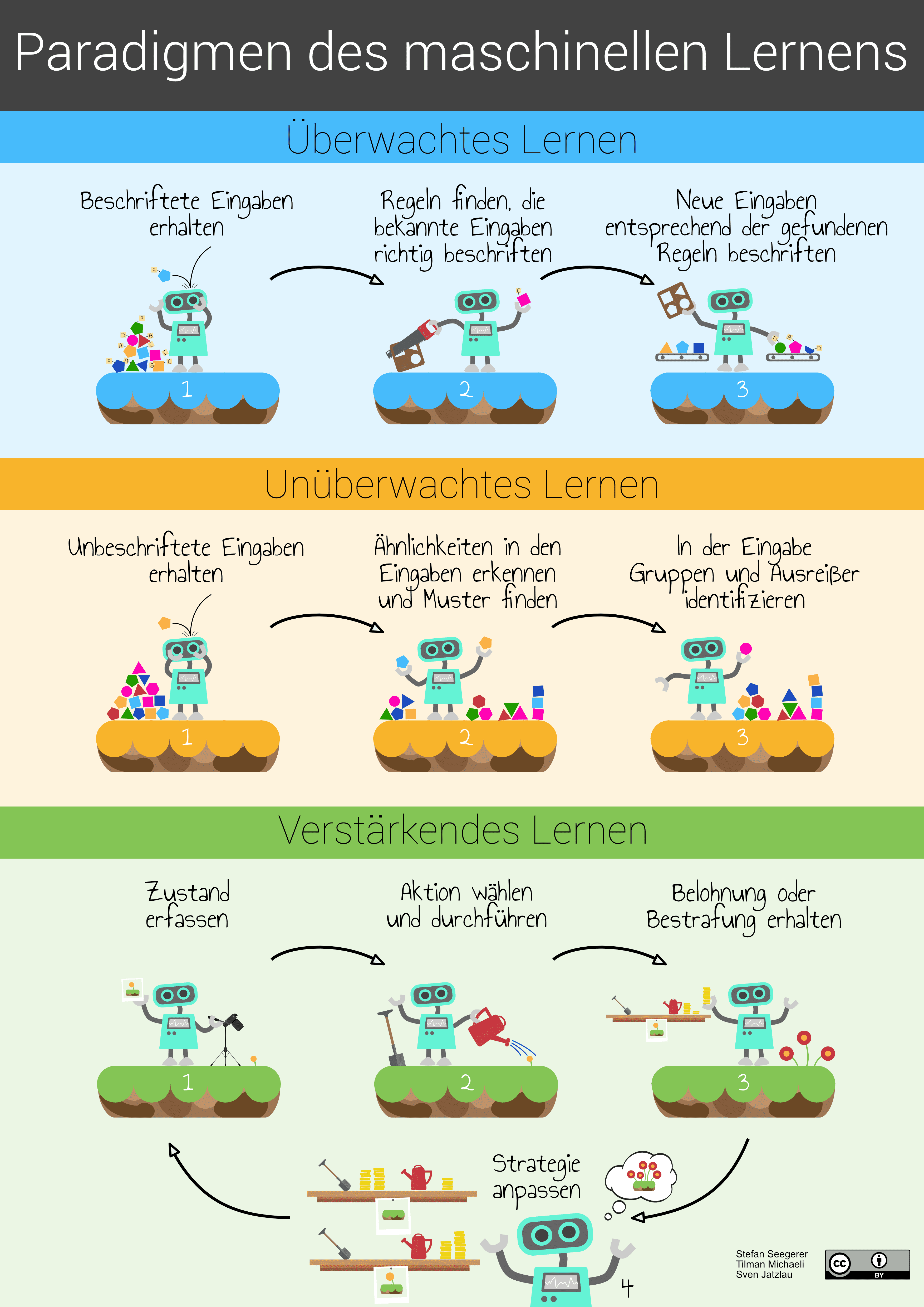
Vergleichbar gehen Verfahren des sogenannten überwachten Lernens vor. Beim überwachten Lernen (supervised learning) stehen eine Reihe von Daten mit entsprechenden Beschriftungen als Eingabe zur Verfügung. Ziel ist es Regeln zu finden, nach denen diesen Eingabedaten jeweils die passende Beschriftung zugeordnet werden kann. Anschließend können diese, in einem Modell erfassten Regeln dann auf beliebige neue Eingabedaten angewendet werden. Die Schritte im Folgenden beschreiben die Aktionen in folgender Abbildung (siehe auch beiliegendes Plakat!).

① Entscheidend für die Verwendung von überwachtem Lernen ist die Verfügbarkeit zahlreicher beschrifteter (oder auch “gelabelter”) Eingaben, die auch Trainingsdaten genannt werden. Das können, wie im Beispiel des Roboters, Bausteine mit der Beschriftung “A”, “B”, “C” bzw. ”D” sein oder Fotos, die mit den Beschriftungen “Katze” bzw. “Hund” versehen sind. Mit etwas Glück können wir dabei auf bestehende Datensätze zurückgreifen. Mit weniger Glück müssen wir selbst die Daten beschriften, die wir als Grundlage für unser Modell verwenden wollen.
② Aus diesen beschrifteten Eingaben stellt das Verfahren selbst Regeln auf, die die Zuordnung der Merkmale der Eingabe (z.B. der Form und Farbe von Bausteinen) und ihrer Beschriftung (z.B. “A”) möglich machen, und verfeinert diese Regeln nach und nach. Auch für die Tierbilder können durch geschickte Verfahren bspw. einfache geometrische Formen identifiziert werden, welche als Merkmale dienen. Da die Beschriftungen der Eingaben aus der Trainingsmenge bekannt sind, kann der Lernprozess “überwacht” werden: Das Verfahren erhält Rückmeldung darüber, ob und inwieweit die aufgestellten Regeln auf Basis der Merkmale die Eingabe bereits mit der richtigen Beschriftung versehen. Auf Grundlage dieser Rückmeldung werden die bisher angenommenen Regeln entsprechend angepasst, um schrittweise zu einem immer besseren Ergebnis zu kommen. Diesen Schritt nennt man auch Trainingsphase. Die Gesamtheit aller Regeln stellt das Modell (für unseren Roboter die Holzschablone) dar, das die erhaltenen Eingaben mit der richtigen Beschriftung versehen soll. Diese Regeln könnten beispielsweise explizit als Entscheidungsbaum oder implizit durch die Parameter eines neuronalen Netzes repräsentiert werden. In der Praxis ist für zufriedenstellende Ergebnisse dabei normalerweise eine große Zahl an Trainingsdaten notwendig, also z. B. mehrere Tausend Bilder von Tieren, die jeweils mit “Katze” oder “Hund” beschriftet sind.
③ Nach Abschluss des Trainings kann das Modell dazu verwendet werden, neue (vergleichbare) Eingaben zu beschriften. Der Roboter kann nun beispielsweise mithilfe seiner Schablone weiteren Bausteinen die Beschriftung A oder B zuweisen. Ein überwachtes Lernverfahren, das darauf trainiert wurde, Katzen und Hunde auf Fotos zu unterscheiden, kann nun auch dazu eingesetzt werden, unbekannte Bilder von Hunden oder Katzen zu beschriften, selbst wenn Blickwinkel oder Lichtverhältnisse des Fotos sich von den Bildern der Trainingsmenge unterscheiden. Bevor ein solches Modell aber tatsächlich zum Einsatz kommt, sollte noch seine Leistungsfähigkeit, also seine Genauigkeit, bestimmt werden. Dafür bietet es sich an, einen Teil der beschrifteten Eingaben, die ursprünglich erhalten wurden, als sogenannten Testdaten zurückzuhalten. Diese werden nun herangezogen, um zu prüfen, wie gut das Verfahren auch diese Eingaben – die bisher nicht für den Lernprozess herangezogen wurden – beschriftet. Je nach Einsatzzweck gibt man sich mit unterschiedlichen Genauigkeiten des Modells zufrieden. Für die Vorhersage, ob ein Kunde auf personalisierte Werbung klicken wird, reichen möglicherweise schon 60% korrekt beschriftete Testdaten, für die Erkennung von Bildern erwartet man eher eine Genauigkeit von 90% und mehr.
Auch wenn das Verfahren aus den konkreten Beispielen verallgemeinern kann, ist es dennoch nicht auf alle Eventualitäten vorbereitet. Im Falle unseres Roboters wird beispielsweise auch ein Halbkreis mit derselben Beschriftung versehen wie der Kreis. Woher soll der Roboter auch wissen, dass ein Halbkreis eine eigene Beschriftung erhalten sollte, wenn er doch vorher noch nie einen Halbkreis gesehen hat?
Einsatzbereiche
Ein großer Teil der kommerziell genutzten KI-Anwendungen basiert auf überwachtem Lernen. Zu den gängigen Einsatzbereichen dieses Lernparadigmas gehören Klassifikations- und die Regressionsprobleme.

Bei Klassifikationsproblemen lernt das Verfahren, wie in unserem Beispiel, Eingaben in unterschiedliche (vorgegebene) Kategorien einzusortieren, ihnen also eine Beschriftung (Label) zuzuordnen. Typische Anwendungsgebiete sind beispielsweise: Zeigt ein Foto eine Katze, einen Hund oder einen Vogel? In welche Risikokategorie fällt ein Kreditnehmer? Ist eine E-Mail als Spam einzuordnen oder nicht?

Darüber hinaus wird überwachtes Lernen bei Aufgaben eingesetzt, in denen Eingaben keine vorgegebene Beschriftung sondern ein numerischer Wert zugeordnet werden soll. Bei solchen Regressionsproblemen wird der zwischen beliebigen Eingabedaten und den als numerische Werte vorliegenden Beschriftungen ermittelte Zusammenhang herangezogen, um später einen Wert vorherzusagen. Mögliche Fragestellungen von Regressionsproblemen lauten dementsprechend: In wie vielen Wochen wird der Nutzer sein Video-Abonnement kündigen? Welchen Verkaufspreis wird ein Haus erzielen? Welchen Kursgewinn wird eine Aktie erreichen?
Unüberwachtes Lernen (unsupervised learning)
Nehmen wir drei große Haufen Legosteine und bitten drei Kinder, die Steine zu sortieren, werden die Kinder auch ohne explizite Anweisung kleine Häufchen bilden, beispielsweise gruppiert nach Farben oder Größe. Ähnlich verhält es sich bei Verfahren des unüberwachten Lernens.
Bei unüberwachtem Lernen (unsupervised learning) stehen lediglich unbeschriftete Daten als Eingabe zur Verfügung. Das Verfahren identifiziert Ähnlichkeiten und Muster in den Eingabedaten selbstständig, etwa um die Daten zu gruppieren oder Ausreißer zu finden.
Die Schritte im Folgenden beschreiben die Aktionen in folgender Abbildung.

① Für einige Probleme stehen weder eine entsprechende Zahl an beschrifteten Daten (wie bei überwachtem Lernen) noch eine Möglichkeit zur Bewertung des Verhaltens (wie bei verstärkendem Lernen) zur Verfügung. Die vorhandenen Informationen beschränken sich auf die unbeschrifteten Eingabedaten: Unser Roboter verfügt lediglich über Daten in Form eines Haufens von Bausteinen. Ein Beispiel aus der Realität könnte hier die Segmentierung von Kundengruppen für die Personalisierung von Werbung sein. Die Eingabedaten sind in diesem Fall Kunden, für die zwar Merkmale wie Alter, bisherige Käufe oder Einkommen zur Verfügung stehen, aber keine Beschriftung wie etwa “technikinteressiert“.
② Unüberwachte Lernverfahren verarbeiten nun die Eingabedaten, indem sie Ähnlichkeiten zwischen Merkmalsausprägungen identifizieren. Im Fall unseres Roboters sind die Eingaben die einzelnen Bausteine und deren Merkmale, also beispielsweise die Anzahl der Ecken. Als Annahme gilt: Je ähnlicher sich diese Merkmale sind, desto ähnlicher sind sich auch die Eingaben. Das gleiche gilt für die Merkmale der Kunden: Je ähnlicher sich Kaufverhalten, Einkommen, Alter, und so weiter sind, desto ähnlicher sind sich zwei Kunden.
③ Ähnliche Eingaben bilden so Gruppen, wie z.B. alle Vierecke für unseren Roboter. Ausreißer, wie beispielsweise der Kreis, liegen isoliert. Aus den Kundendaten ergeben sich ebenso verschiedene Gruppen. Für das Ausspielen von Werbung müssen wir uns nun die gefundenen Gruppen näher ansehen und entscheiden, welche Werbung für welche Kundengruppe angemessen ist.
Die Zuordnung der Eingaben zu Gruppen anhand ihrer Merkmalsausprägungen stellt hier das Modell dar, das mit jeder neuen Eingabe weiter angepasst wird. Im Unterschied zu überwachtem Lernen haben wir aber keine Beschriftung dieser resultierenden Gruppen, sondern lediglich die Information, welche Daten einer Gruppe zugehörig sind. Außerdem können wir die Güte des entstandenen Modells nicht objektiv beurteilen, da im Gegensatz zum überwachten Lernen keine Aussage möglich ist, ob eine getroffene Zuordnung “richtig oder falsch” ist.
Einsatzbereiche
Unüberwachtes Lernen kommt insbesondere in Situationen zum Einsatz, in denen keine beschrifteten Eingabedaten zur Verfügung stehen oder dies mit hohen Kosten verbunden wäre. Auch deshalb wird unüberwachtes Lernen manchmal zur Vorverarbeitung von Daten eingesetzt, die beispielsweise in Gruppen zugeordnet und dann für überwachtes Lernen als beschriftete Eingabedaten verwendet werden können. Gängige Einsatzbereiche sind daher das Clustern von Daten, das Finden von Anomalien oder das Identifizieren von Zusammenhängen.

Das Identifizieren verschiedener Gruppen (Cluster) aus den Eingabedaten findet auch bei Clusteranalysen oder im Topic Modelling Anwendung. Topic Modelling ist ein Ansatz, um die Themen von Textdokumenten automatisiert zu identifizieren. Dazu wird die Ähnlichkeit von Textdokumenten auf Basis der enthaltenen Wörter bestimmt. Daraus ergeben sich Gruppen von Textdokumenten mit gleichem Thema (Topic).

Das Gegenteil von Clustering stellt die Anomalieerkennung dar, bei der der Fokus – statt auf der Gruppierung von Daten – auf Ausreißern liegt. Anwendung findet das etwa in der Analyse von verdächtigem Netzwerkverkehr oder der Betrugserkennung bei Kreditkartenzahlungen.

Darüber hinaus werden unüberwachte Verfahren eingesetzt, um bisher verborgene Zusammenhänge (Assoziationen) in Daten zu finden. Beispielsweise werden beim Online-Shopping Kaufempfehlungen auf Basis des aktuellen Warenkorbs gegeben: Kunden, die teure Armbanduhren kauften, kauften in 70% der Fälle auch hochwertigen Whiskey.
Verstärkendes Lernen (reinforcement learning)
“Aua, heiß!” – Sehr schnell werden Kinder nach ihren ersten Erfahrungen mit einer Herdplatte gelernt haben, dass man diese besser nicht berühren sollte… Dabei lernen Kinder durch die direkte Rückmeldung ihrer Umwelt.
Verstärkendes Lernen (reinforcement learning) ist ein von der Psychologie inspiriertes Paradigma des maschinellen Lernens: Der Agent – ein Computerprogramm, das zu autonomen Verhalten fähig ist – lernt in Interaktion mit seiner Umwelt durch wiederholte Belohnungen oder Bestrafungen die Erfolgsaussichten seiner Aktionen besser einzuschätzen und somit seine Strategie zu optimieren.

Im Unterschied zu den beiden bereits betrachteten Paradigmen werden beim verstärkenden Lernen vorab keine großen Datenmengen (weder beschriftet noch unbeschriftet) benötigt. Der Agent verfolgt ein Ziel, das er erreichen möchte, etwa erfolgreich das Spiel Snake zu spielen, oder, im Falle unseres Roboters, eine Wiese mit ganz vielen Blumen zu bepflanzen. Was der Agent dazu jedoch erst lernen muss, ist die passende Strategie.
① Zunächst erfasst der Agent den Zustand, also die relevanten Aspekte seiner Umwelt. Für unseren Roboter ist dieser beispielsweise durch den Wachstumsstand der Blumen gegeben. Im Falle von Snake würde die Position des Futters und aller Teile des Schlangenkörpers den Zustand darstellen.
② Innerhalb seiner Umwelt kann der Agent nun Aktionen ausführen, die er je nach Zustand der Umwelt aus einer Menge verfügbarer Aktionen auswählt. Unser Roboter hat in jedem Zustand dieselben zwei möglichen Aktionen zur Auswahl: gießen oder mit dem Spaten Setzlinge pflanzen. Bei Snake kann sich die Schlange entweder nach oben, unten, rechts oder links bewegen. Durch das Ausführen einer der verfügbaren Aktionen verändert sich der Zustand der Umwelt.
③ Anschließend wird der Agent nach im Voraus festgelegten Regeln belohnt oder bestraft. Wenn unser Roboter sich im Zustand “Setzlinge bereits gepflanzt” befindet und durch die Aktion “Gießen” zum Wachstum der Setzlinge beiträgt, wird er mit einer festgelegten Anzahl Münzen belohnt. Gräbt er stattdessen mit dem Spaten die Setzlinge wieder aus, wird er bestraft und ihm werden Münzen abgenommen. Bei Snake wird etwa belohnt, wenn sich der Kopf der Schlange dem Futter nähert, und bestraft wenn die Schlange ihren eigenen Schwanz berührt. Die Art und Weise, wie Belohnung und Bestrafung vergeben werden, hat erheblichen Einfluss darauf, wie der Agent lernt. So ist es nicht undenkbar, dass ein autonomes Fahrzeug lernt lieber kein Gas zu geben, da Stehenbleiben nicht bestraft wird, die Bestrafung bei einem Unfall aber im Vergleich viel zu hoch wäre.
④ Während Belohnung den Agenten dazu verleitet, Verhalten häufiger zu zeigen, führt eine Bestrafung dazu, dass dieses Verhalten von nun an seltener an den Tag gelegt wird. Erfolgreiche Aktionen werden also “verstärkt”, ungeeignete Aktionen “verlernt”. Auf diese Art und Weise passt der Agent seine Strategie an, die in seinem Modell gespeichert wird. Wird vom Lernvorgang des Agenten gesprochen, ist damit eine Anpassung des Modells gemeint. Unser Roboter verwaltet seine Strategie über das Regal, in dem er für jeden Zustand eine aktuelle Bewertung der möglichen Aktionen pflegt.
Zunächst wird der Agent aufgrund fehlender Erfahrung dabei explorativ vorgehen und Aktionen zufällig auswählen. Durch wiederholtes Durchlaufen des Zyklus aus Zustand erfassen, Aktion auswählen und ausführen sowie Belohnung oder Bestrafung erhalten, optimiert er seine Strategie nach und nach.
Einsatzbereiche

Ein häufiger Einsatzbereich für verstärkendes Lernen sind Spiele. Der Zustand der Umgebung lässt sich relativ leicht erfassen, die beste Aktion oder der beste Zug hängt jedoch von einer Reihe von Faktoren ab. Aufgrund dieser Komplexität lässt sich also kaum ein klassischer Algorithmus finden, um auf alle Eventualitäten des Spiels reagieren zu können. In unzähligen Spielrunden und Partien lernt der Agent das entsprechende Spiel zu meistern.

Auch Roboter oder selbstfahrende Autos können mit verstärkendem Lernen trainiert werden. Hier wird man allerdings oft auf Simulationsumgebungen zurückgreifen, ehe man Roboter oder Autos in der echten Welt Erfahrungen sammeln lässt.

Ein weiterer Einsatzbereich sind Optimierungsaufgaben: Probleme, die mathematisch kaum lösbar sind und bei denen nicht klar ist, welche Strategie am besten funktionieren wird. Das könnte etwa die Steuerung der Heizung oder die Planung von Zugverbindungen sein. Bei Ersterem lernt der Agent die Heizung bei gleichzeitiger Minimierung der Heizkosten so einzustellen, dass immer die richtige Temperatur herrscht. Im zweiten Fall versucht das Verfahren eine Strategie zu entwickeln, bei der alle Verbindungen mit einer möglichst hohen Zugauslastung bedient werden können.
Maschinelles Lernen als gesellschaftliches Phänomen
Maschinelle Lernverfahren gewinnen zunehmend an Bedeutung in immer mehr Lebensbereichen und erzielen dabei erstaunliche Ergebnisse. Und das, obwohl Computer dabei kein Verständnis des Problems im eigentlichen Sinne entwickelt, sondern lediglich Muster und Regeln in Daten identifiziert haben.

Das bedeutet jedoch gleichzeitig, dass maschinelle Lernverfahren dabei auf ihren spezifischen Einsatzzweck festgelegt sind. Sollte etwa unser Roboter statt Bausteinen nun Hunde- und Katzenbilder beschriften müssen, wird er (ohne neue Trainingsdaten) hoffnungslos verloren sein.
Darüber hinaus ist der Erfolg maschineller Lernverfahren sehr abhängig von den zur Verfügung stehenden Daten, aus denen gelernt wird. Da maschinelle Lernverfahren aus einer zwar großen, aber doch begrenzten Menge an Daten lernen, übernehmen sie mögliche Verzerrungen in diesen Eingabedaten. Im Falle unseres Roboters gehen wir davon aus, dass die Verteilung der Bausteine, mit denen er trainiert wird, mit der der weiteren Bausteine übereinstimmt – eine Annahme, die in der Realität eben oft nicht zutrifft.

Ein weiterer Punkt, in dem sich maschinelle Lernverfahren von konventionellen Algorithmen unterscheiden, ist, dass getroffene Entscheidungen sehr viel schwieriger nachzuvollziehen sind, da es oft kaum möglich ist zu erkennen, welche Zusammenhänge in den Daten der Algorithmus nutzt. Wird beispielsweise die Vergabe eines Kredites auf Basis eines maschinellen Lernverfahrens verweigert, lässt sich nicht immer rekonstruieren, warum der Algorithmus dieses Ergebnis liefert, was insbesondere im Falle eines Fehlers zu weitreichenden Konsequenzen führen kann. Ein Ansatz, dieser Problematik zu begegnen, wird unter dem Begriff Explainable AI gefasst. Hier wird versucht, die Ergebnisse maschinellen Lernens nachvollziehbar zu machen.

Wenn aber vom Computer getroffene Entscheidungen nur noch schwer nachvollziehbar sind oder auf Basis verzerrter Daten getroffen werden, gehen damit auch ethische und rechtliche Fragestellungen einher, die von uns als Gesellschaft diskutiert werden müssen. Voraussetzung dafür ist, dass möglichst viele Menschen über die entsprechenden informatischen Grundlagen verfügen und die dem Phänomenbereich maschinellen Lernens zugrundeliegenden Ideen und Konzepte verstanden haben sowie deren Möglichkeiten und Grenzen einschätzen können.
Übersichtlich dargestellt sind die drei Arten wie maschinen Lernen können im Poster, das Sie hier herunterladen können:
- Poster So lernen Maschinen (Deutsch)
- Poster Types of Machine Learning (English)
- Poster Types of Machine Learning (Korean)
Siehe auch: